

Comprehensible
We focus on visual and understandable results which break down complex connections into easy parts. Statistical results will always be brought into a comprehensible format.

Modern
Through our involvement in the scientific community, we apply algorithms, that are constantly evolving and keeping ahead on the state of the art. Whats possible changes every day, and we enjoy to be a part of this.

Safe
A lot of datasets contain private or confidential information which needs to be handled accordingly. We make sure that every data transfer is up to modern standards.
Telecommunication
The application on customerbehaviour of a telecommunication company made the classification of customers into different groups possible. New knowledge about the behaviour of customer groups could be found. Of special interest were customers with a high probability of cancelling their contract soon.
Stock Market
The analysis by application of self organizing algorithms onto 8000 on the US stock market traged companies led to a novel segmentation of the stock market. Based on that knowledge it was possible to derive the probability of a value increase in stocks. The prognosis has proven to be successfull in generally bad markets.

Gene Analysis
In an analysis of DNA microarray data, it was possible to extract the most relevant for disease prognosis in a data set of about 4000 gene data. The reduction to resulted in 19 particularly relevant genes. Only this enormous reduction in complexity allows further investigation of the genes for their exact function. Initial studies suggest a new understanding of tumor growth in a common type of tumor in children (neuroblastoma).

Sport Medicine
The investigation of multivariate time series on limb position and muscle activity during inline skating with the Time Series Knowledge Mining method revealed interpretable temporal patterns describing the typical coordination of muscles in the movement process. These findings can be used for rehabilitation measures and training control.
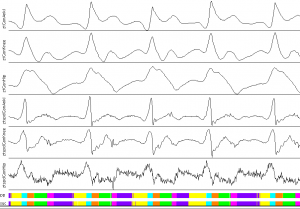
Medical Diagnosis
An example from medicine is the diagnosis of diseases of borrelliosis or meningitis based on an analysis of the cerebrospinal fluid (CSF). The largest group (red) that emerges in the U-Sphere represents the uninfected patients. The other groups represent subforms of the infection, some of which are not yet known.

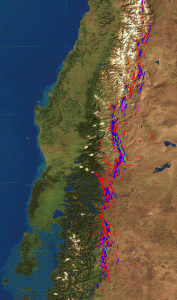
Mointain Wave Projekt
The Data Bionics group is involved in the Mountain Wave project. Here, flight data, e.g. from record flights from the Andes, are analyzed. The goal is to advance meteorological knowledge about the occurrence and shape of atmospheric lee wave structures (mountain waves).